Vertex と Python を使用した Google LLM ファミリーの AI モデルの微調整
微調整は、事前トレーニングされた AI モデルに基づいて AI モデルを特殊化するための強力な武器です。プロンプトと比較して、新しい AI モデルを最初から開発するよりもコストがはるかに安くなり、出力の精度をさらに高めることができます。
この記事では、Vertex と Python を使用して Google LLM ファミリーの AI モデルを微調整する方法を詳しく説明します。行きましょう!
目次: Python を使用した Google AI モデルの微調整
AI モデルの微調整とは
AI モデルの微調整は、独自のデータセットを使用して事前トレーニングされた AI モデルに基づいて出力をカスタマイズし、精度を高めるプロセスです。微調整の目的は、事前トレーニングされた AI モデルの元の AI 機能を維持しながら、より特殊なユースケースに適合するように調整することです。微調整を通じて既存の洗練されたモデルの上に構築することで、機械学習開発者は特定のユースケースに効果的なモデルをより効率的に作成できるようになります。このアプローチは、事前トレーニングされたモデルを最初から作成する必要がないため、計算リソースが限られている場合や関連データが不足している場合に特に有益です。
たとえば、あなたはブロガーでありソーシャル メディア コンテンツ作成者であり、モデルを微調整して、スタイリッシュな口調でコメントに返信できるようにしたいと考えているとします。声。さらに、あなた独自の口調で価値提案を行ってブログ記事を書くこと。この場合、微調整は、ワークフローと統合することでタスクを展開および自動化するためのオプションです。
Google AI モデル チューニングのためのデータ準備
Vertex AI 言語セクションのチューニングを使用すると、開発者はこれら 2 つのキー (input_text と Output_text) を使用して JSON データをフォーマットする必要があります。開発者は他の人とキー名を変更することはできません。
Input_text は、プロンプト、コンテキスト、または AI によって純粋に生成されたコンテンツのサンプルを追加するためのものです。逆に、output_text は、input_text がプロンプトのようなものである場合に、AI が期待する答えを育成する場所です。ブロガーやソーシャル コンテンツ作成者を例に挙げると、投稿、記事、またはその他のコンテンツ形式のサンプル全体を、output_text 部分に追加できます。
データセットの準備ができたら、それを JSON 行に変換する必要があります。これは、Google Vertext AI 言語のチューニングに必要な形式であるためです。 Pandas データフレームを使用したサンプルは次のとおりです。
<プリ><コード>
df2.to_json('ファイル名.jsonl'、orient='レコード'、行=True)
pdRead = pd.read_json('yourfilepath.jsonl'、lines=True)
チューニング モデルの作成
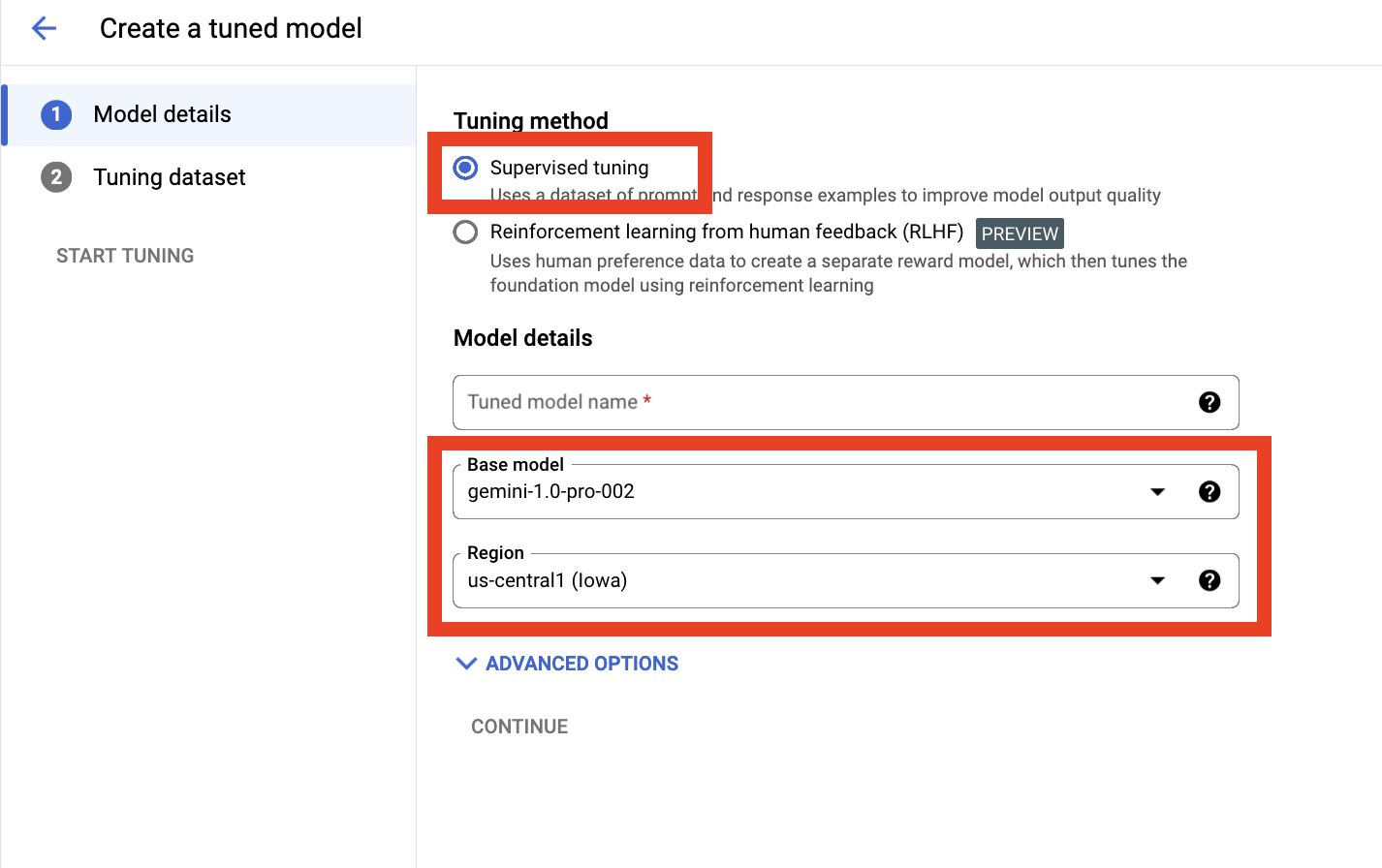
すべてのデータセットの準備ができたら、Google Cloud Vertex に移動します。 Google クラウド アカウントを作成し、Vertex Studio に移動して言語セクションを選択し、クリックして次の画像のように調整および蒸留タスクを作成します。
次に、メソッド、モデル、リージョンなどをさらに選択する必要があります。教師ありモデルの Gemini と us-central は次のとおりです。
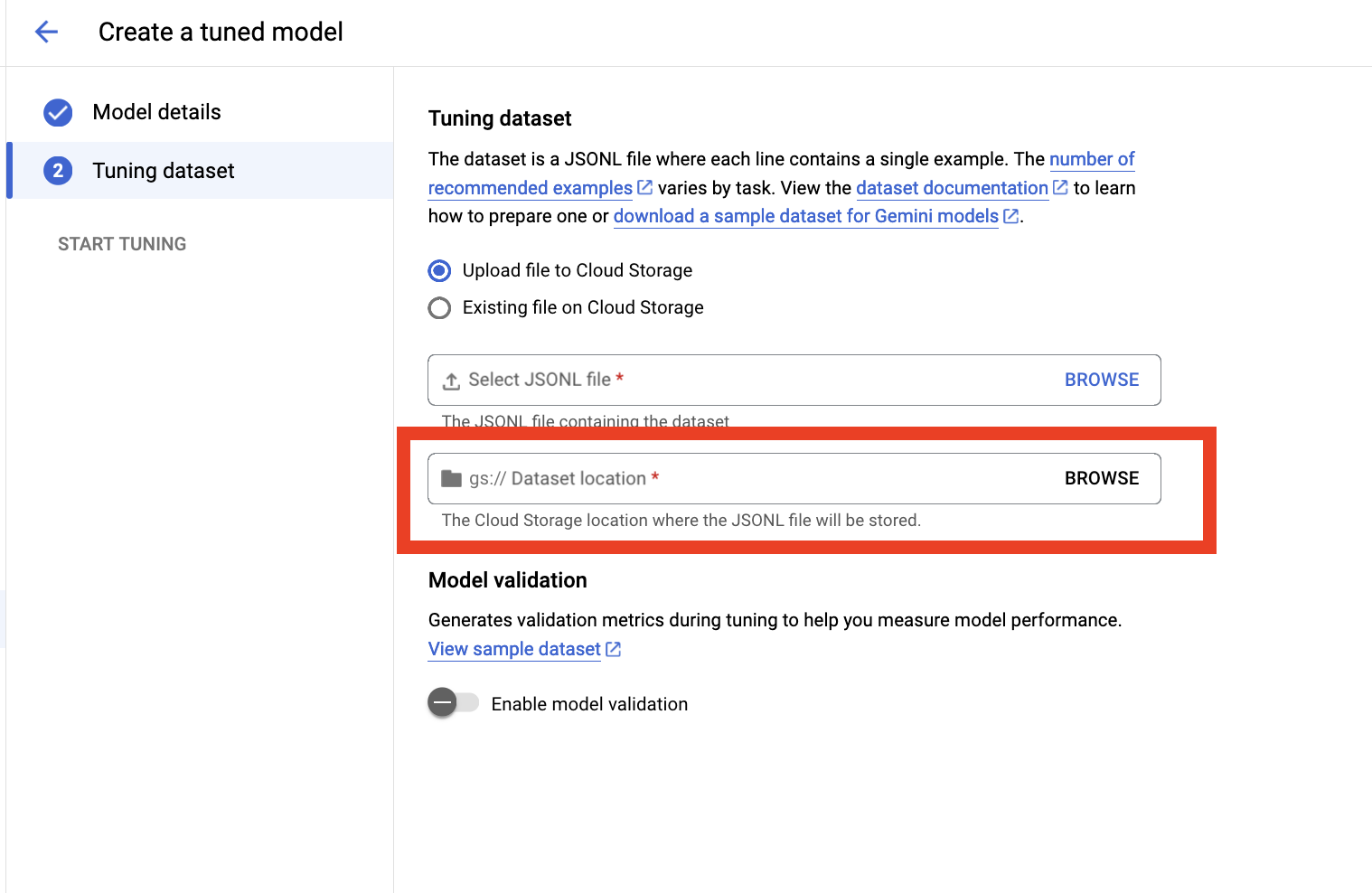
最後に重要なことですが、準備した JSON 行データセットを Google Cloud ストレージにアップロードし、ここで選択する必要があります。
保留中のチューニングと Python を使用した呼び出し方法
モデルのチューニングのプロセス中に、パイプラインに移動してステータスを確認したり、言語セクションに戻ってステータスを確認したりできます。この期間は、事前トレーニングされたモデルの調整に使用しているデータセットによって大きく異なります。私の場合、完了までに約 5 時間かかります。
チューニングが完了したら、モデル ガーデンに移動し、所有するデータセットを使用してチューニングに使用したモデルを即座に選択できます。または、Python を使用してテストすることもできます。以下はスクリプトのサンプルです。
<プリ><コード>
deftunedModel(自己、プロンプト、文字):
パラメータ = {
"max_output_tokens": int(文字),
「温度」: 0.9、
"トップ_p": 1
}
model = TextGenerationModel.from_pretrained("AI モデルのバージョン")
model222 = model.get_tuned_model("プロジェクト/プロジェクトID/場所/リージョン名/モデル/調整されたモデルID")
応答 = model222.predict(
プロンプト、
**パラメータ
)
応答のテキストを返す
Google AI モデルのチューニング コスト
Vertext チューニングの料金の詳細については、Google it にアクセスし、公式 Web ページで更新されたコンテンツを確認することをお勧めします。コストの面では、コンテンツ制作を目的としたモデルのチューニングに使用しました。 1回あたり平均100ドルを費やします。 EN 文字数は毎回 350,000 文字で、所要時間は約 5 時間です。これらの数字が Google AI チューニングを使用したコストに関する参考になれば幸いです
OpenAI または Azure AI と比較すると、費用は同様ですが、場合によっては後者の方が料金が安くなる場合があります。それはケースバイケースで異なります。
まとめ
微調整は、専門的でニッチな目的に特化した同等の低コストの最先端の AI モデルを入手するための強力な武器です。コストが節約され、ゼロから開発するための投資は必要ありません。
"